DraftSync
A production-grade AI editorial engine with parallel non-blocking pipelines, adaptive RAG, and a verification system that flags its own uncertain claims. Built in three days for the Wealthsimple AI Builders program.
The Problem
Editorial teams rely on AI writing tools that produce output that looks finished and authoritative, but contains unverifiable claims, fabricated statistics, and hallucinations. Most AI content tools optimize for the illusion of completeness rather than the reality of editorial judgment. Editors need a system that treats AI output as a draft with annotations, not a final product.
The Solution
DraftSync is an AI-native editorial engine that ingests real-time SEO intelligence, retrieves editorial style context from a vector database, generates complete article drafts with header images, and flags its own uncertain claims for human review. Every component runs in parallel where possible and degrades gracefully where it must.
- 1. Parallel non-blocking pipelines — SEO fetch, text generation, image generation, and RAG retrieval all run concurrently with independent error boundaries. No pipeline blocks another.
- 2. Two-deployment retry chain — cascading retry with explicit error detection and a structured fallback draft scaffold when all LLM calls fail. The editor never sees a blank page.
- 3. Adaptive RAG thresholding — cascading similarity thresholds from 0.4 to 0.0 with random corpus fallback. Style context from pgvector always arrives, with provenance transparency in the UI.
- 4. [[VERIFY]] claim annotation system — the model wraps every unverifiable statistic, date, or benchmark in verification markers. A dedicated panel lets editors approve, edit, or search each claim before publishing.
Architecture
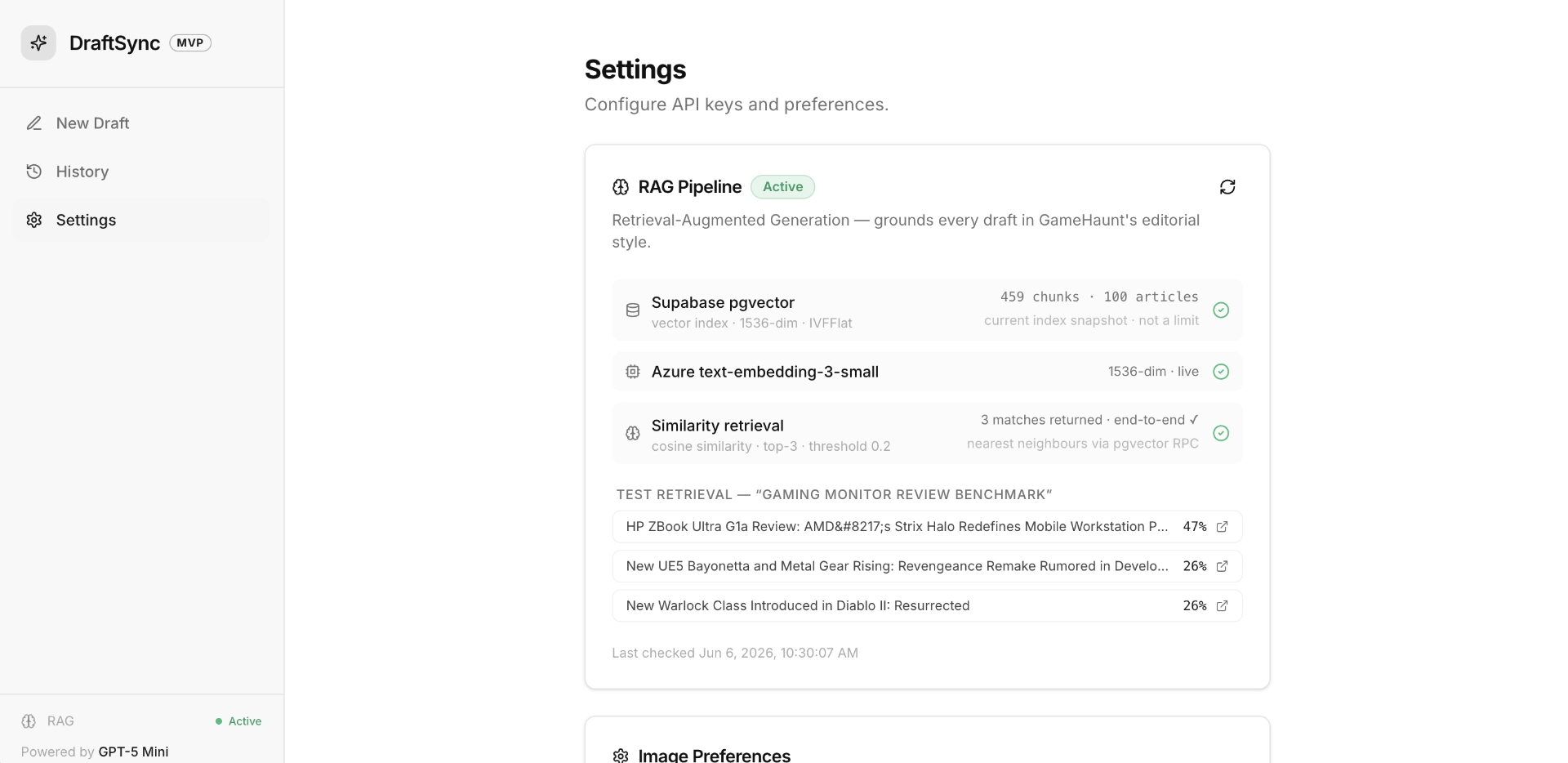
The architecture is deliberately decoupled. SEO data is awaited because the generation prompt needs it. Everything else runs detached. The user sees the SEO panel populate first, then the draft starts streaming, then the header image appears, then RAG provenance badges arrive last. Perceived latency is the time of the slowest individual component, not the sum of all of them.
What Shipped
Design Philosophy
The central principle: AI output should never be presented as authoritative. DraftSync produces output that looks like a draft with annotations, not a finished article. The system never lies about what it knows or how it knows it.
Every component has a fallback and every fallback is visible to the user. Response headers expose the full chain: whether the draft came from AI or fallback, which provider generated the image, and the specific error that triggered any degradation. Dual-path persistence means drafts written during a Supabase outage are saved to localStorage and merged back when the connection returns.
Read the full architecture deep dive
The complete post covers parallel pipeline design, retry chains, adaptive RAG thresholding, the [[VERIFY]] annotation system, dual-path persistence, and two-stage image generation with transparent fallbacks.
Read the architecture deep diveInterested in building a production AI editorial system? Get in touch to discuss AI content workflows, RAG pipelines, or multi-agent editorial systems.